AI A/B testing optimization (2025): what it is and why it matters
AI A/B testing optimization uses statistical learning and machine learning to adapt traffic allocation, quantify uncertainty, and personalize decisions during an experiment—not just at the end.- Adaptive allocation: send more traffic to better variants (multi‑armed bandits) while capping risk.
- Better inference: use Bayesian posteriors and CUPED variance reduction to reach confidence faster.
- Smarter segmentation: uplift modeling finds who benefits, not just what wins on average.
- Guardrails: protect revenue, latency, and churn with real‑time monitors that can pause or roll back.
Design tests the AI way: hypotheses, priors, power, and guardrails
AI doesn’t replace good design. It amplifies it.- Clear hypothesis: state the user behavior you expect to change and why.
- Primary metric: conversion, activation, ARPU, or task completion—pick one as your decision metric.
- Priors: use historical conversion as a weak prior for Bayesian analysis; keep it conservative.
- Power and MDE: estimate detectable lift with realistic variance; use variance reduction (e.g., CUPED) when possible.
- Guardrails: error rate, latency, refund rate, unsubscribe rate—set thresholds for auto‑pause.

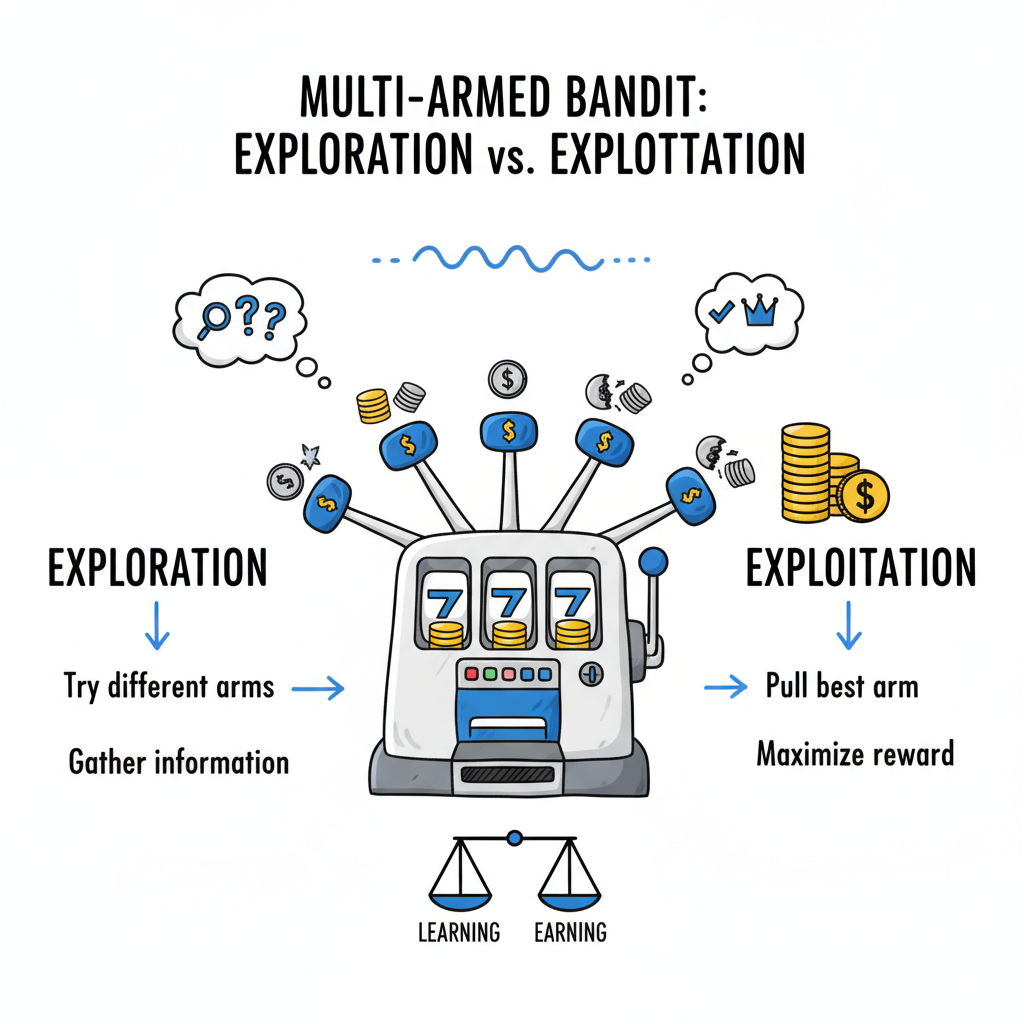
Bayesian, sequential, and bandits: pick the engine for your funnel
You have three powerful approaches. Use each where it shines.- Bayesian A/B: model conversion with Beta‑Binomial or Normal approximations. Report P(variant > control) and expected lift with credible intervals. Works well for most web funnels.
- Sequential testing: peeking‑safe tests (e.g., alpha‑spending) let you check progress without inflating false positives. Good when you need frequent checks.
- Multi‑armed bandits: algorithms (Thompson Sampling, UCB) reallocate traffic to winners during the test, minimizing regret. Best for always‑on creatives and high‑traffic placements.
Variance reduction and sample efficiency
- CUPED (pre‑experiment covariates): subtract predictable variance using historical behavior, reducing required sample size.
- Stratification: analyze within traffic tiers (device, channel) to avoid Simpson’s paradox and noisy mixes.
- Covariates: include recency/frequency or baseline propensity to stabilize estimates.
Personalization and uplift modeling (beyond averages)
Average wins can hide losers. Uplift models estimate the incremental treatment effect per user segment.- When to use: big, heterogeneous audiences with enough data (e.g., large e‑commerce, SaaS trials).
- Signals: device, geography, traffic source, prior activity, customer tier.
- Models: two‑model approach (response and control) or direct uplift (e.g., transformed outcome trees).
- Actions: route high‑uplift users to variant; keep low/negative uplift on control.
Practical applications and playbooks
- Landing pages: auto‑allocate traffic to value prop that lifts paid signups; guardrail CPA and bounce.
- Pricing: test presentation (monthly vs annual emphasis); protect churn and refund rates.
- Onboarding: sequence tooltips and checklists; bandit picks next best nudge by step completion.
- Email subject lines: Thompson Sampling across variants each send; throttle losers fast.
- Creative rotation: always‑on bandit for ads; bias toward new creatives with priors, then learn.
Expert insights: truth, trust, and transparency
- Declare decision rules up front; stop on criteria, not vibes.
- Show uncertainty: credible intervals and probability of superiority build stakeholder trust.
- Avoid metric overfitting: choose one primary; keep guardrails simple and few.
- Instrument everything: log exposure, eligibility, assignment, and versioning (model, code, config).
- Bias checks: verify randomization balance; watch for cookie loss and tracking gaps.
Rules vs ML optimization vs bandits vs uplift: where each wins
- Rules only: fast but brittle; fine for tiny tests.
- Bayesian AB: best default for clear decisions and narratives.
- Sequential tests: when you must peek often.
- Bandits: high traffic, many creatives, continuous allocation.
- Uplift: large data, heterogeneous effects, personalization payoff.
Implementation guide: ship AI A/B testing in 10 steps
- Pick one funnel: high impact, stable traffic (e.g., pricing page CTA).
- Define metrics: one primary (conversion/ARPU), 2–3 guardrails (latency, refunds, unsubscribes).
- Instrument: event logging for exposure, assignment, conversions, and covariates.
- Choose approach: start Bayesian A/B (Beta‑Binomial) with credible intervals; set stop rules.
- Variance reduction: add CUPED using prior‑period behavior.
- Automate checks: balance tests, guardrail monitors, anomaly alerts, and auto‑pause.
- Bandit rollout: move to Thompson Sampling for always‑on creatives after your first win.
- Segment sanity: inspect key segments; only ship uplift targeting if stable.
- Docs & governance: store configs, priors, and decisions with versioned code.
- Scale: templatize analysis notebooks; add a weekly experiment review ritual.
Tooling stack (verified categories)
- Experiment platforms: Optimizely Full Stack (server/client), VWO Testing (web), Firebase A/B Testing (apps). Verify current capabilities on official docs.
- Stats libraries: Statsmodels (frequentist), PyMC/NumPyro (Bayesian), scikit‑learn (uplift via custom pipelines).
- Data/ETL: your warehouse + notebooks/DBT for CUPED and reports.
- Monitoring: alert when guardrails breach or randomization drifts.
Reporting: what stakeholders actually need
- Decision headline: ship/hold/rollback, with probability of superiority and expected lift.
- Uncertainty: credible interval or peeking‑safe CI; note sample size and duration.
- Guardrails: show deltas stayed within thresholds.
- Learnings: segment insights, UX feedback, and next iteration plan.
Pitfalls and how to avoid them
- Peeking without correction: use sequential methods or Bayesian posteriors; don’t eyeball p‑values daily.
- Dirty data: dedupe users, handle cookie loss, and exclude bots; log eligibility.
- Too many variants: screen with small traffic; prune aggressively before bandits.
- Metric soup: one primary metric; treat others as guardrails or diagnostics.
Related internal guides (next reads)
- AI Automated Report Generation 2025 — automate experiment reporting and QA.
- AI Lead Qualification Systems 2025 — route high‑intent traffic revealed by experiments.
- Mobile App Security Best Practices 2025 — keep experiment SDKs safe and compliant.
- App Store Review Guidelines 2025 — ensure experiment flags don’t violate policies.
Authoritative references (verify current docs)
- Optimizely: Bayesian testing • VWO: A/B Testing docs
- Firebase A/B Testing • Statsmodels • PyMC
- Microsoft: CUPED variance reduction
- Airbnb Engineering: experimentation posts
Final recommendations
- Start with one high‑impact funnel and a Bayesian A/B to prove the loop.
- Add CUPED and guardrails to move faster without breaking things.
- Promote proven variants via bandits for always‑on gains.
- Pilot uplift targeting only when data is large and stable.
- Document priors, rules, and outcomes—your compounding edge is repeatability.
Frequently asked questions
What’s the fastest way to start AI‑powered A/B testing?
Instrument one funnel, run a Bayesian A/B with credible intervals and guardrails, and document stop rules. Layer CUPED next.When should I use a bandit instead of classic A/B?
Use bandits for always‑on creative rotation or high‑traffic surfaces where minimizing regret matters during the test.How do I avoid “peeking” mistakes?
Use sequential methods (alpha spending) or Bayesian posteriors. Don’t interpret classical p‑values mid‑test without correction.Is uplift modeling worth it for small sites?
Usually no. You need scale and stable segments. Start with simpler tests; add uplift when you have data depth.How do I set guardrails?
Pick 2–3 critical metrics (e.g., latency, refunds, unsubscribes) with clear thresholds and automatic pause rules.Can I use historical data in my test?
Yes—CUPED uses pre‑experiment behavior to reduce variance without biasing the treatment effect.How many variants are too many?
Screen many variants quickly, then prune. Keep 2–3 strong contenders for the main test or bandit.What’s the best way to present results?
Lead with decision, probability of superiority, expected lift, and credible intervals. Show guardrail compliance and next steps.Disclosure: Some links are affiliate links. If you buy through them, we may earn a commission at no extra cost to you. Always verify features, limits, and policies on official vendor sites.
